You are here

Chris - Thu, 2012/05/24 - 18:11
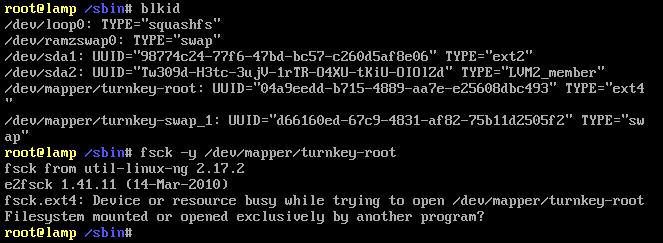
This appliance has been working for several weeks. For some reason, after being rebooted, we are now prompted with the (initramfs) prompt.
BusyBox v1.13.3 (Ubuntu 1:1.13.3-1ubuntu11) built-in shell (ash)
Enter 'help' for a list of built-in commands.
(initramfs)
We have searched through the forums and tried a couple of things but nothing seems to work the way they are explained on the articles we found.
I have attached the output from blkid and fsck commands in the attachement.
Any help would be greatly appreciated.
Attached:
{kind=link}
Forum:
Tags:
You will need to run fsck from a live CD
You shouldn't ever run fsck on a mounted filesystem. Running the fsck command (as shown in Chris' screenshot) should work when run from a live CD.
I have exactly the same
I have exactly the same issue. Booting from the live CD I get the same results as Chris. Trying to run
fsck -y /dev/mapper/turnkey-rootYou get the error device or resource busy trying to open /dev/mapper/turnkey-root
file system mounted or open by another program.
Any ideas
thanks
Paul
Resolved this issue by
Resolved this issue by booting from slax live cd and running
fsck -y /dev/mapper/turnkey-rootIt did not work from Turnkey live cd as partitions are mounted ?
Should I see a /dev/mapper/turnkey-root folder in turnkey12.0?
I had a fine turnkey linux mysql server with expanded disk space done by using LVM2. I used some tips somewhere from these message boards to set it up, as the default turnkeylinux shipped partition is WAY WAY too small to do any serious database work for me. The instructions are perfect, and the machine has been running stable for months (inside virtualbox, hosted on win764bit)
Then the host system crashed for some unrelated reason (bluescreen), and when i restarted the VM it ended up in BusyBox v1.17.1 Debian 1.17.1-8turnkey+2+gdaf9f75
/dev/disk/by-uuid/5e5cdc5d-xxxxxx does not exist
As I am not really doing anything linux in my day to day work, i had to google and read a lot, and while getting wiser i started to investigate using methods that probably won't break anything.
inside the busyBox ash shell :
(initramfs)lsblk
/dev/sda1:uuid="0ced0ed7xxxx" TYPE="ext2" (this one is referenced in grub as a msdos something)
/dev/sda2:uuid="h6Fvwxxxx" TYPE="LVM2_member"
/dev/sdb: uuud="ShhkgV-xxxx" TYPE="LVM2_member"
None of these three have the UUID that grub is trying to boot onto, which is stated in grub as
/dev/disk/by-uuid/5e5cdc6dxxxxx
I have two disks installed in the vmbox, and the sdb is likely the big one of them (the one I half a year ago used to expand disk space to make room for the database) the sda2 is probably residing on the original partition on the original turnkeylinux disk. The filesystem seem to be missing the /dev/by-uuid entry for whatever partition it used to boot into.
(initramfs)ls /dev/mapper
I do not get anything in there except one file called control
in particular i don't get a /dev/mapper/turnkey-root file or directory
This is inside the ash console. In the posts above, that is - normally - would they have shown /dev/mapper/turnkey-root if one did a ls /dev/mapper ?
is the change bc my turnkey is newer or begause it is brorken?
In this case, how should i proceed with fschk or other measures to bring back up the server?
It seems the two volumes with the LVM2 are recognized - is there any way i could get data out from them?
Further, it seems that other volumes are perhaps partially recognized :
if i do a ls /dev/by-path i get 5 entries:
pci-0000:00:01.1-scsi-1:0:0:0 -> ../../sr0
pci-0000:00:0d.0-scsi-1:0:0:0 -> ../../sdb
pci-0000:00:0d.0-scsi-0:0:0:0 -> ../../sda
pci-0000:00:0d.0-scsi-0:0:0:0-part1 -> ../../sda1
pci-0000:00:0d.0-scsi-0:0:0:0-part2 -> ../../sda2
This reveals a ../../sr0 partition what is that?
if i do a ls /dev/by-uuid i get only 1 entry:
0ced0ed7-xxxx (the one that i think the ash has booted into or is running from - its mentioned first in grub) -> ../../sda1
how come only one is listed? wouldn't there be more at this point in boot if all was well?
if i do a ls dev/by-id i get
9 scsi-SATA_VBOX_HARDDISK_VB671f68fb-47a94594 -> ../../sdb
9 ata-VBOX_HARDDISK_VB671f686fb-47a94594 ->../../sdb
9 scsi-SATA_VBOX_HARDDISK_VB9e8209ac-4ca55a96 -> ../../sda
10 ata-VBOX_HARDDISK_VB9e8209ac-4ca55a96 -> ../../sda
10 scsi-SATA_VBOX_HARDDISK_VB9e8209ac-4ca55a96-part1-> ../../sda1
10 scsi-SATA_VBOX_HARDDISK_VB9e8209ac-4ca55a965-part2-> ../../sda2
I am working on getting an earlier version of this server up running to go take a look at how it looks like when all is well, but the server is impractically huge so just importing the image into virtual box takes hours (and deleting a lot of stuff to make space for it)
I have only worked from inside ash to reduce the risk of breaking something, i have also tried to boot to /dev/sda1 (by editing the boot text inside grub temprorarily by pressing e and replacing the uuid with /dev/sda1) which failed with errors about missing directories. in ash,and in grub,
in grub i get
ls
(hd0)
(hd0,2)
(hd0,1)
(hd1)
grub>ls (hd0)
device hd0:Partition Table
grub>ls(hd0,1)
Partition hd0,1:Filesystem type ext2 - modification time- UUID 0ced0edxxxxx (the one mentioned first in grub, i think the one that ash is being booted into)
grub>ls(hd0,2)
Partition hd0,2:Unknown Filesystem
Could this be my missing UUID partition?
grub>ls(hd1)
Partition table
btw the grub has this entry for the menu chosen
insmod part_msdos
insmod ext2
set root='(sd0,msdos1)'
search --no-floppy --fs-uuid --set 0ced0ed7xxxxxx (the one that ash seems to boot into, the one that ponts to sda1 in dev/disk/by-uuid)
echo 'loading Linux 2.6.32-5-686'
linux /vmlinuz-2.6.32-5-686 root=UUID=5e5cdc5d-6563xxxxxx
(the 5e5cdxxxx UUID mentioned above is totally nowehere to be seen)
I am learning lots of new stuff here, but I don't really know what to do next - I don't feel I have a clear idea of why the UUID 5e5cdc5d is not in there when i do a ls /dev/by-uuid in ash and i'm not sure if grub can see that partition - and if it can't, how to make it visible again.
I haven't had any disk crashes or the like, all that happened was a sudden poweroff due to a host crashing unexpectedly - could the problem be something that is fixable, some partition table that needs to get restored or fixed or something?
Any help is very much appreciated - i am in way too deep. Let me know if You need further info to pinpoint whatever the problem might be.
Btw. is it normal that a linux system that looses power goes dead like this? or is it the LVM stuff that's causing problems? I'm a bit puzzled that a poweroff made a partition seem to go away, would not expect that to happen - i mean - why would the OS write to critical parts of disk files when operating normally?
Could it be that the OS has turned something off for maitainance? if so - is there any log files i might be able to investigate to see what has happened? If so - how do I access those files (and where) now that the system won't boot?
I am a newbie linux user, but I should be able to follow ordes, read info in links etc.
In advance, thanks a lot everyone
SOLUTION - replace uuid with prior setting from backed up server
SOLUTION
Okay, this is pretty strange.
The backup copy of the server (except less records in the database the server has not been tampered with by any humans as far as i know) has this grub 1.98-1ubunti9 setting :
insmod part_msdos
insmod ext2
set root=(sd0,1)
search --no-floppy --fs-uuid --set 0ced0ed7-d2b0-4013-9fe5-7ba9adef1e2e
linux /vmlinuz-2.6.32-5-686 root=/dev/mapper/turnkey-root ro
(note! above line is not the same as the crashed server)
What i did now on the crashed server was :
in the boot menu (get it by holding down shift) press E when the top line is highlighted
change the uuid reference in grub from the =root=uuid reference to =/dev/mapper/turnkey-root
then ctrl-x to boot
and.. hey presto the server booted up like it should, and all is well, mysql is up running again.
Question!! WTF (what-the-fuck) changed that line in grub from /dev/mapper/turnkey-root to an uuid that doesn't work?
Is there some auto-update going on, that went wrong reg. the grub setup?
I recon I'll have the exact same problem next time i restart as the bad UUID is still in grub, but I'll figure a way to change it.
Pretty pleased to get my 1.3 trillion records back online..
I suspect that the change wasn't in Grub
I would think that the change was actually in the Volume UUID itself (not the entry in Grub). AFAIK the UUID is stored within the first few blocks of the volume. If that area of the volume (and/or the UUID itself) is corrupted/damaged/missing then the volume UUID needs to be recalculated. If the volume is marginally different (due to corruption - even if only minor and not affecting any obvious operation of the machine) to what it was previously then the UUID will be different.
So what I think has happened for you is that some corruption on the host HDD has caused the first (virtual) block or two to cause the UUID to be regenerated thus causing a mismatch between the current UUID and the one stored in Grub. I find that it'd be highly unlikely that it is an issue with Grub itself (although who knows...).
This situation is probably a good reminder that backups of any data that you can't afford to lose is essential. Rememeber that data loss is a matter of when - not if! Personally I love TKLBAM but if that is no good for then find something else that does work for you. Personally I also keep local backups (as well as TKLBAM) so that I have both a quick easy local backup as well as offsite backup. With a good backup you could have potentially saved yourself tons of time and effort and just restored your backup to a fresh appliance instance...
I don't think the UUID has
I don't think the UUID has changed. Even if it has, the UUID referenced in the grub on the "new, cannot boot" machine is exactly the UUID of the partition that is referenced by /dev/mapper/turnkey-root :
"old, can-boot-by-itself" version, GRUB shows this line to boot
linux /vmlinuz-2.6.32-5-686 root=/dev/mapper/turnkey-root ro
and when i boot the "new, cannot-boot-by-itself" version, GRUB shows this line to boot :
linux /vmlinuz-2.6.32-5-686 root=UUID=5e5cdc5d-6563-4508-8802-c9bbb0ef6931
On the "new, cannot boot by itself" , i have the following uuid mappings once it is running (i get it going by holding shift, then pressing e to edit the boot stuff in grub and replace the uuid line with the /dev/mapper line)
root@mysql /dev# blkid
/dev/sda2: UUID="H6FvwE-6TaN-DWzN-HlsB-gfQk-372P-Vb8ueR" TYPE="LVM2_member"
/dev/mapper/turnkey-swap_1: UUID="18c27337-f98f-489b-989c-1fcd8e67c43e" TYPE="swap"
So.. the older backup of the server boots to a /dev/mapper/turnkey-root location, while the newer version seems to boot to an UUID that is not known or resolvable by the booting system at that time, to the same place. Once we're flying, the UUID that it tried to boot to, turns out to in fact be the /dev/mapper/turnkey-root volume (logical LVM volume)
Fun stuff is - I certainly haven't changed grub or stuff like that myself, as I didn't even know of those things before the server didn't boot properly. My TKL linux stuff has worked so well that I, in fact, have not have had to spend much time learning how to set up and manage linux servers.
I remember faintly that perhaps on a boot at some time, the server either asked me if it should upgrade itself, or it did by itself, but other than that, I'm pretty sure I havent changed anything myself between the old backup, and the running version.
A few reboots before the old backup was taken, I extended the disk space by adding a physical disk and extending the LVM as per forum hints, but that worked out just fine.
I agree very much with Your concerns reg. backup. I back up the entire server from time to time, and on another fixed schedule, the data inside of it is backed up - working with so much data, it's pretty slow to import it all, so it's in fact faster to fire up a fairly recent backup of the entire server to get running, and then handle the lost data window from backups after that. Once I have server or data backups, they are duplicated on different disks and machines. You'd have to burn down the house, or steal the host running the server, as well as the two machines holding backups to make me loose data, which is the level of protection i need at the moment. It would take a simultaneous wipe of 3 or 4 harddisks on 3 different pc's before i'd start to REALLY get worried, and the files reside on 3 different OS's so a software bug or virus would have to be pretty clever to get them all. Backups are not overwritten, their names are different - so a sudden loss will not propagate back in time.
Anyway, I can only agree that the only sane way of planning is to expect software to fail, hardware to fail and plan systems and procedures that take care of that *when* it happens.
heh -yea' "just restore to a
heh -yea' "just restore to a fresh appliance" is a road i've been down a few times after i messed something up, or some hardware failed in a more than usually harmful way.
I have so much data in the largest database table that restoring into a fresh mysql database takes about 3 to 4 days.
Importing a backed up server to virtualbox, in comparison, only takes about 3-4 hours or so.
So Usually i deal with the (relatively smaller) data loss since last server backup later, and go for the latest server backup to get something running quite fast.
Add new comment