You are here

unaffectedoddball - Fri, 2015/01/16 - 17:49
It takes several seconds to simply vzctl enter the appliance. Hitting Enter takes a few seconds to return the cursor.
Fresh install, no updates yet. Downloaded from:
http://www.turnkeylinux.org/download?file=openvz/debian-7-turnkey-postgr...
top - 15:38:49 up 34 min, 0 users, load average: 0.00, 0.00, 0.04 Tasks: 23 total, 1 running, 22 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.0 us, 0.1 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem: 8388608 total, 3280528 used, 5108080 free, 0 buffers KiB Swap: 4194304 total, 0 used, 4194304 free, 79908 cache
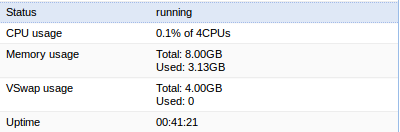
Other machines on the node are running fine. Resource consumption on the node is attached.
Attached:
{kind=link}
Forum:
Tags:
Have you run the inithooks scripts yet?
Once you have then it should run fine (although TBH I haven't checked...
Also FWIW others have mentioned that TKL OVZ containers run at 100% CPU until a mod is made to the OS config. Personally I haven't had that issue, but I run under Proxmox so perhaps that is relevant to other versions of OVZ (other than the one PVE supply)?
You should be able to find that thread here somewhere (if running the inithooks doesn't work...). Also (obviously) double check that it's not something up with your host (inc other OVZ containers hogging resources) and/or you have given the particular guest enough resources...
Let me know how you go. If need be I can test an instance locally pretty easy and can see if I can reproduce your issue.
Thanks for the response. From
Thanks for the response. From what I have learned, the inithooks are those that run upon first login:
I did run this and set the root password, skipped the hub services, and did not install any updates. Please let me know if this lag is reproducable or if it is only affecting my environment.
Thanks!
Yep, they'e the ones...
Now that I see your top results and your screenshot I can see that it has tons of resources and that wouldn't be the issue... (Although FWIW the screenshot looks more like the guest rather than the host).
I don't know what the size of your dataset is, but after a bit of a google it seems that a large (>1GB) PostgreSQL dataset on OpenVZ can be a little slow... I didn't find a lot of consensus nor very much info but I did find a page on the OpenVZ wiki which has some hints...
There may be some tuning measures that can be done to improve it?
Having said that, I note that you mention that just entering the machine is slow... That seems like it is perhaps more than just an issue with PostgreSQL itself... So you are running other TurnKey OVZ containers ok? Perhaps test a KVM PostgreSQL appliance out of interest. Either install from ISO or create the machine with a 20GB vmdk and from the commandline overwrite the default vmdk with the TurnKey VMDK image.
I could test a PostgreSQL appliance on my Proxmox setup if you want...
Yes, please test this in your
Yes, please test this in your environment. I have no dataset since all I have done is literally installed the container and run the inithooks. Other resources on this node are running fine; both containers and VMs. I've even destroyed and reinstalled the TKL PostgreSQL and see the same slow behavior with out doing anything other than defining the database password when running the inithooks. And as I said, it's just as pokey after installing all updates.
Tests fine for me...
I just launched a fresh TKL v13.0 amd64 PostgreSQL OVZ template. And it all works fine OOTB. I haven't done anything other than create it and boot it, then run the init scripts.
FWIW the init question about updates is redundant in OVZ templates as they install security updates on initial boot. When using Proxmox I use the WebUI (NoVNC) console window so I know when it has finished installing updates. Then I usually login via SSH to run init scripts (although that shouldn't make any difference I wouldn't think).
My VM (CT technically) has much lower specs than your's too; 1xvCPU and 512MB RAM. It is currently idling at 0.2% CPU and 174MB RAM. Getting into the VM via SSH (from my laptop on the same LAN) is very fast and
vzctl enter [VMID]is almost instant.The only other thing that I did different was that I downloaded the template via the Proxmox WebUI (rather than direct from TKL mirror network) although that shouldn't matter (as PVE downloads from TKL mirror network too). The only thing that I could think of is perhaps some minor corruption of the template? Perhaps check the image integrity. Don't just download again without first checking properly...
Interesting. I actually
Interesting. I actually installed mine using a Proxmox template too. I only included the link in case a non-Prox user wanted to help and needed to know which version of the TKL I was using. I believe they are bit-for-bit identical whether they're downloaded from TKL or via the Proxmox template feature.
I don't expect a corrupt image would even boot, let alone provide a somewhat usable CT. What I did do was radically scale back my resources and immediately noticed lightning-like response times. I'm now running a single CPU in 2 GB of memory.
I ran unixbench on a CentOS CT with similarly big specs and noticed that the multi-processor test actually performed slower than the single threaded test. I'm getting the impression that adding more vCPUs to a CT is nothing like adding more CPUs to a real server.
Thanks for your testing and feedback!
Hmm yes very weird...
The templates download from the TurnKey mirror network regardless of whether you do it through Proxmox or via download link. So yes they should be binary identical.
FWIW you'd be surprised what a slightly corrupt download will do... I have had experience with a TKL ISO. It installed fine and appeared to run fine after install, but would have weird behaviour at times (services crashing and refusing to restart without a reboot IIRC - I don't recall exact detail; it was quite a few years ago now). After running out of options on why it wasn't working I checked the ISO integrity and sure enough it was corrupt. I downloaded again and that too had the same result (it seems that my closest mirror had a corrupt copy). I used a different mirror and the integrity checked out and all was well. FWIW; without doing a proper integrity check I wouldn't have known and would have assumed that it was a TurnKey issue... The ISO reported as being exactly the right size (I compared the corrupt and non-corrupt side-by-side) It was only the integrity check that showed there was something wrong!
Anyway, I digress... Your tests are very interesting... It might even be worth posting/asking over on the Proxmox forums and/or the OpenVZ forums to see what that is all about... I have never allocated more that 2 vCPUs on a container (my home PVE server only has 2 anyway - although the one I administer/support has 4.
Another thought. You don't mention your host hardware (sorry if you did and I missed it...) but keep in mind that many Intel CPUs have hyper-threading and will report twice as many CPUs as they really have. Whilst in a desktop OS that may be of some value; as a headless server (especially as a VM) the usefulness is less so. The additional reported "hyper-thread CPU cores" are essentially just allowing you to use some of the wasted CPU cycles on a real CPU core. So whilst 2 process threads can simultaneously run on a single core (i.e. 'hyperthreaded'), they are really sharing it's performance and whilst together they may equal more that 100% performance of a single thread on a single core (due to utilising some CPU cycles that would otherwise be wasted) it will not equal 200%. It is probably more like ~110% +/- performance overall (so each thread is actually only getting ~55% +/- performance of a single thread running on a single core).
I'm not sure whether that applies to you, but I thought it may be worth mentioning...
huh. I responded Friday but I
huh. I responded Friday but I guess it didn't make the board.
I don't think our hardware is to blame. We're running a trio of server-class machines with :
2 X 8-core 2.0 GHz CPU
64 MB RAM
Interestingly enough, I ran UNIXbench on the CT and the results are below (higher=better):
1-vCPU:
767.5
4-vCPUs:
single thread: 728.7
4 paralell processes: 589.6
8-vCPUs:
single thread: 728.2
8 paralell processes: 828.1
So unless I want to dump tons of resource at it, I'm really better off using a single processor; at least in this test.
My suggestion would be to ask on the Proxmox &/or OpenVZ forums
You might find someone there that has some ideas on what might be the issue and/or how they/it might be resolved/worked around...
Thanks. Maybe I need to start
Thanks. Maybe I need to start a new thread for this but figured it might be something simple.
I'm still experimenting and destroyed the container and rebuilt it, and now I can't enter the container. It just hesitates about two seconds then comes back with:
Rebuilt it a couple times and it keeps kicking me out. I can log in via the NOVNC just fine. What gives? What logfiles can I monitor?
thread forked
See this post for vzctl enter problem
Add new comment