You are here
New Hub feature: Server snapshots
I usually get excited when adding new features to the TurnKey Hub. Recent excitement included server monitoring, reserved instances, domain management, and the Hub API.
I'm very excited about todays annoucement, not only is it awesomely useful, it's also technically cool!
So what are snapshots?
I'm sure you can guess, but let me explain anyway.
Snapshots can be used with EBS-backed instances to create point-in-time snapshots of the root filesystem, which are persisted to Amazon S3 for storage durability. Snapshots are incremental, meaning that only changes since the last snapshot are saved, taking up less storage, time, and reducing costs (see below for technical details).
Snapshots ask Amazon's fiber-optic storage backplane to save your server's disk state while it's running without impacting performance.
Ok, but what can I do with them?
Server clones
Snapshots can be used as the basis for a new server, essentially creating a clone (the cloud server equivalent of a time machine crossed with a portal to a less obnoxious alternative dimension), for example:
- You can clone a production server to create a staging enviroment for testing new features, hacking away, whatever, without the worry of hosing your production server (guess how I tested this new feature).
- You can essentially upgrade your servers hardware if you need the extra horse power, memory or even disk space. Say you were testing an idea with a micro instance, and now its taking off. Firstly congrats, secondly just clone the micro's latest snapshot to a larger instance size and update the DNS record / re-associate the elastic IP.
- Let you're imagination run wild!
EBS Volumes
Snapshots can be used as a starting point for a new EBS volume, for example:
- You mistakenly deleted a file, hosed your database, or whatever bad thing that can happen. You create a volume from the snapshot of your choice, attach it to your instance (which is auto-mounted via ebsmount) and access the data you need.
- Again, let you're imagination run wild!
Can I schedule automatic snapshots?
You sure can! You can schedule automatic zero-load server snapshots for hourly, daily, weekly and monthly frequency, or manually create one at anytime.
There is however a snapshot limit per Amazon account, per region, so when configuring automatic scheduled snapshots, snapshot retention is also configurable to prune old snapshots, keeping you within the limit and saving you money.
Sounds cool, what does it look like?
We've added 2 new fields to the server record:
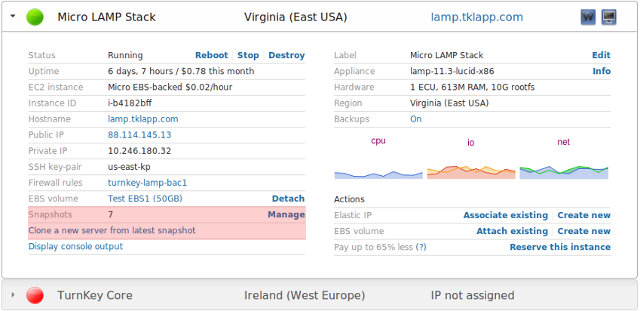
And this is the snapshot dashboard:

Are there any limitations?
Snapshots only support EBS-backed instances, and not S3-backed instances. This is a technical limitation as snapshots are performed on the EBS-backed root volume, which S3-backed instance do not have.
Snapshots are saved to S3 storage, but they will not appear in your S3 buckets, nor can you access them using the standard S3 API. To access snapshot data you need to create an EBS volume or a server clone.
As mentioned above, there is a limit of the amount of snapshots each Amazon account can have, but you can request to increase your limit (specify you want the snapshots limit increased in the comments.)
Data consistency: Do not solely rely on snapshots for backups, as they may become inconsistent due to disk-buffering and locking. We use TKLBAM for our backups, and suggest you do the same.
Technical details - snapshots explained
I mentioned that snapshots are technically cool, and that they are incremental - let me try and explain what that means at how it works behind the scenes.
A snapshot of an EBS volume can be taken at anytime, which asks Amazon's fiber-optic storage backplane to save the data stored on the volume, at the block level, at that exact point-in-time, to S3 storage.
To improve performance and reduce storage space, Amazon will only copy the blocks of the volume that have changed since your last snapshot - hence incremental.
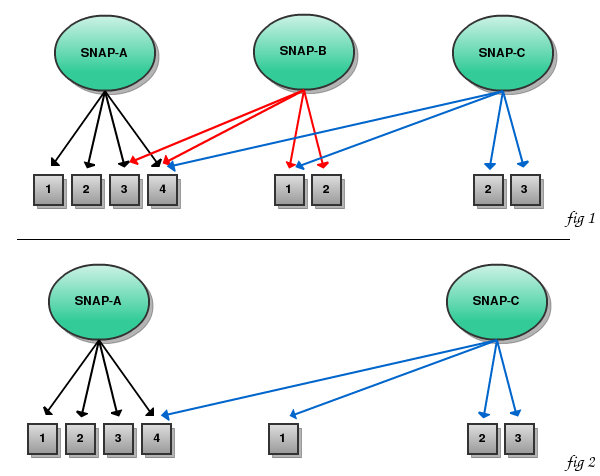
Now for the extra cool part, unlike regular incremental backup chains, you can delete any previous snapshot. Huh? What? Yep, snapshots are not chained, but are rather conceptually like a table-of-contents of pointers to saved data blocks.
When you delete a snapshot, only the data blocks that are solely used by that specific snapshot are deleted. Data blocks that are used by subsequent snapshots are not. In the below illustration, if SNAP-B is deleted, only SNAP-B:block-2 will be deleted from Amazon S3 as a newer version (SNAP-C:block-2) has already been saved.
Bottom line, take snapshots for a spin and let us know what you think.
Comments
Nice one Alon!
Looks good mate. Another nice complement to the TKL/Hub lineup!
Very Interesting.. I use these in ESXI and will be great here!
I need to spend some time testing this... I ran a snapshot yesterday then tried to build a new Cloud but I think I missed some elements... Once I get the method down though I expect it will be extremely helpful.. I already noticed how fast this will build a new server.
As always, learning the protocol is where to start.
Thanks for the hard work!
Slightly different process but able to build new server frm Snap
In VMware you "revert" to a Snapshot. In TKL Hub, you build a new server from snapshot.
ONe command then needs to be issued.
IP Address generally needs to be reassigned.
it works,,, or did so today anyway quite nicely.
Benefits over TKLBAM
I have just read through very quickly and either I have missed soimething or I am thick - aside from ease of use what is the benefit over TKLBAM?
Also is Postgres supported from snapshots?
Chris Musty
Director
Specialised Technologies
From my understanding
This new 'snapshot' feature is fundamentally different to TKLBAM in that it is a whole filesystem image (think 'snapshot' in VBox or VMware) and thus PostgreSQL (and any end user modifications/inclusions/exclusions) are supported without any technical knowledge or tweaking required.
So whilst it's not a replacement for TKLBAM it could be an easy way to 'clone' existing instances and/or revert to a previous state. I guess one downside would be that the size would be significantly larger (compared to TKLBAM). One obvious upside (as mentioned above) is that server customisations are included without need to tweak anything.
You've got it around the wrong way...
Snapshots are whole of disk. TKLBAM backups are req'd data only (and thus much smaller). Both snapshots and TKLBAM backups can be incremental (ie just save the changes between the original backup and the current machine state).
That is why snapshots aren't a replacement for backups! Although snapshots can be very handy, they are not a replacement IMO.
If the server is not running then snapshots are ok
Snapshots can be a useful "quick and dirty" tool, but unless you want to regularly stop your server, they are not a reliable backup (due to data volatility within a running server; e.g. perhaps a file is halfway though being written when you take the snapshot!?).
There are also some other considerations to keep in mind:
You pay for storage on Amazon, admittedly it's pretty cheap, but it can add up (I cleaned a couple of particularly large snapshots that I had forgotten about recently, saving me $70/mth). Snapshots are essentially a complete copy of your filesystem (AFAIK at a block level). This means that they include the full OS which makes them big! OTOH TKLBAM backups only contain what it needs to; then compresses it. That makes them small! And that's just the "full" backups, the incrementals are much smaller again.
A server snapshot is that server's filesystem at a particular point in time. If you launch a new server from a snapshot; for all intents and purposes, the new server IS the old server (at that point in time). It will contain all the configurations of your original server - including things like hostname, HubDNS configuration, SSH and SSL key(s) and certificates.
Assuming that you understand the implications of that, from a development standpoint it is probably not really an issue (e.g. you can adjust the hostname, regenerate secrets, etc). However for a production server (unless the new server is to replace the old one) it is a bad thing. It has serious security implications!
You can work around them if you wish, but none of those shortcomings apply to a TKLBAM restored backup. A new server with a restored TKLBAM backup is a new server, but with the old server's data!
A clone from a snapshot contains all the all the old package versions (at least until turnkey-secupdates runs next). Whereas assuming that you allow the secupdates to run on firstboot; a TKLBAM restore will include all the latest security patches. Other issues you may encounter from a "cloned" snapshot are the new server "stealing" the HubDNS configuration of the original host (and probably the original server stealing it back again later; and so on...). Also, if you are using TKLBAM as well then unless you manually intervene, the 2 separate servers will continue to back up to the same TKLBAM backup record (they both think that it belongs to them). That will almost certainly cause major issues down the track when it comes time to restore!
Pages
Add new comment